
LLM for Dummies - PART 1
(Part 1)

We've all heard the buzz… "We're exploring GenAI capabilities," or the company focus of the month is on "LLMs and GenAI." But what do these terms really signify? They certainly have a ring of sophistication, but is it feasible to implement an LLM on your systems?
It seems like GenAI is the latest frenzy, akin to the Bitcoin boom—cue the 'to the moon!' memes
.

Definition: LLM - Large Language Model. The acronym entered the popular lexicon around 2022, following OpenAI's release of Dall-E and ChatGPT.
INTRODUCTION
.
At the core of LLMs lies the ambition to mimic human-like text processing, enabling machines to read, comprehend, and respond to human language in a coherent and contextually relevant manner.
Simply put, a large language model (LLMs) is a type of model that uses deep learning to process natural language and learn relationships between words, phrases and sentences - often trained on large datasets from various sources, such as books, articles, websites, and scripts.
"Large language models are few-shot learners. They are trained to perform a wide variety of tasks without task-specific training data." OpenAI
In this blog post, we will kickstart our journey with a glimpse into some "Key Concepts" that form the bedrock of LLMs—don't worry if they don't all click right away, we'll circle back to them as we progress.
Next, we'll explore the ‘History’ that set the stage for their evolution and finally dive into the basic mechanics of how LLMs work. A deeper awaits in Part 2 of this series.
.
If you haven’t read my first post about Machine Learning, Click Below
1st Rule of Machine Learning

Machine learning (ML) is a powerful tool, but it's not always the first solution we should turn to… Rule 1 of Machine Learning: “Don’t use Machine Learning” . No Machine Learning you say? Diving straight into ML can be tempting, especially with the buzz it has generated. However, ML requires a robust data pipeline, high-quality…
5 QUICK IMPORTANT CONCEPTS
(1) Tokenisation

Tokenisation is the process of breaking down text into smaller pieces, called tokens. These tokens can be as small as characters or as long as words. This is the first step in preparing text for use in machine learning and NLP tasks.
By converting text into tokens, we transform the messy, unstructured text data into a structured format that's easier for models to learn from.
.
(2) Word Embedding

Embeddings are a type of word representation that allows words to be represented by dense vectors where a vector represents the projection of the word into a continuous vector space. One of the significant advantages of Word Embeddings is their ability to capture semantic relationships between words. For instance, vector operations can capture relationships like "King" - "Man" + "Woman" ≈ "Queen".
.
(3) Attention Mechanism
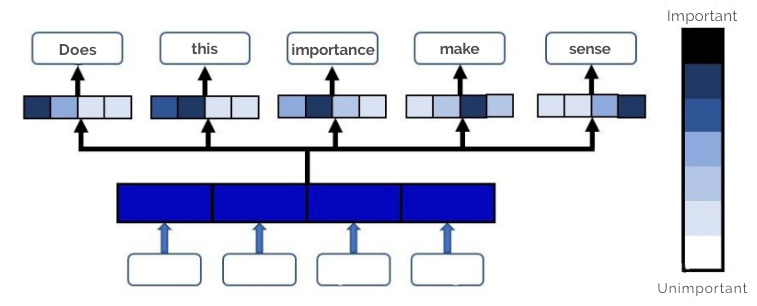
The Attention Mechanism is a technique used in neural networks to prioritise certain parts of the input data, enabling the model to focus on different sections of the input sequentially rather than processing the entire input at once.
It helps models to handle long sequences of data efficiently, making it crucial for tasks like translation - for example, in machine translation, when translating a sentence from English to French, the attention mechanism helps the model focus on one word at a time, finding the corresponding translation.
.
(4) Size and Scalability of LLMs
.
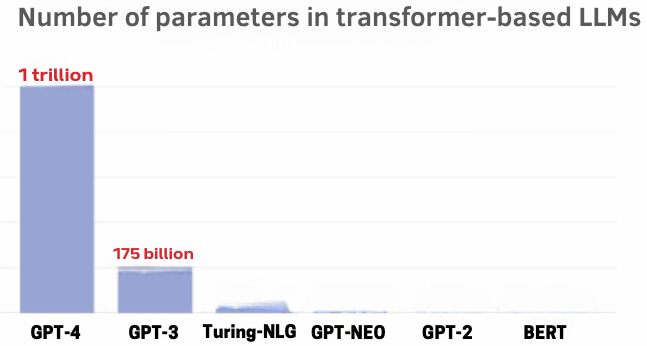
The "size" of an LLM typically refers to the number of parameters it has. A parameter is a part of the model that's learned from the training data. Larger models, with more parameters, can often learn more complex patterns in data, but they also require more data to train effectively and are more computationally intensive.
GPT-4, one of the largest LLMs, boasts 175 billion parameters, enabling it to learn and generalise across a vast array of topics and tasks.
(5) Transfer Learning

Transfer Learning is a machine learning strategy where a model trained on one task is adapted for a second related task. It's a powerful way to leverage pre-existing models (that might have been trained on vast datasets) for new tasks where data might be scarce, saving time, computational resources, and achieving better performance even with less data.
A good example is BERT, a pre-trained language model, which can be fine-tuned to perform various NLP tasks such as sentiment analysis, named entity recognition, and more, showcasing the versatility of transfer learning.
HISTORY

.
1950s - 1960s: Early NLP
The infancy stage of Natural Language Processing (NLP) during the 1950s and 1960s was marked by the development of rule-based systems. The premise was straightforward: encode linguistic rules into machines to make sense of text. Initial models operated on formal grammars (a set of rules defining the structure of a language), with the main challenge being the “disambiguation of linguistic constructs” or in simple terms, clarifying meanings of words based on context.
Although these systems could perform basic tasks such as syntax parsing (analysing the structure of sentences) and text generation based on predefined rules, they lacked the ability to generalise across varied linguistic patterns and truly grasp context.
As the field navigated through these early challenges, several notable figures and pioneering projects emerged, significantly impacting the trajectory of NLP
Noam Chomsky: A prominent linguist, philosopher, and cognitive scientist, Chomsky introduced the Chomsky Hierarchy and the concept of generative grammar, which had a profound impact on computational linguistics and the development of NLP.
Joseph Weizenbaum: In the 1960s, Weizenbaum developed ELIZA, one of the earliest examples of a natural language processing program. ELIZA could simulate conversation and showcased the potential of machines in language-based interactions.
IBM's Shoebox: In the early 1960s, IBM demonstrated the Shoebox machine at the World's Fair, which could recognise spoken digits and a limited set of words, marking an early endeavour into speech recognition.
1997: Birth of LSTM, Neural Networks
The year 1997 marked a significant milestone in the NLP realm with the introduction of Long Short-Term Memory (LSTM) networks by Sepp Hochreiter and Jürgen Schmidhuber. LSTMs were designed to address the vanishing gradient problem (a challenge in training deep neural networks where gradients of loss function tend to become very small) that plagued traditional Recurrent Neural Networks (RNNs, a type of neural network well-suited for sequence data), thus enabling the handling of long-term dependencies in sequential data—a crucial aspect for processing language.
LSTMs brought a novel architecture into the foray, embedding a memory cell and three multiplicative gates—namely the input, output, and forget gates—to govern the flow of information. This allowed LSTMs to capture long-term dependencies in sequential data - recognising relationships between elements spaced far apart in a sequence - which is key for processing language.

By mitigating the vanishing gradient snag, LSTMs could facilitate the back-propagation (a common algorithm for training neural networks) through time training algorithm, allowing for deeper and more complex neural networks.
2003-2013: Word Embeddings
The period between 2003 and 2013 marked the emergence of word embeddings. Techniques like Word2Vec, introduced by Mikolov et al. in 2013, and GloVe (Global Vectors for Word Representation), introduced by Pennington et al., re-defined how words were computationally represented.

Moving away from treating words as discrete symbols, word embeddings situated words in continuous vector spaces (mathematical spaces where words are mapped to vectors of real numbers), thereby capturing semantic relationships and similarities between them efficiently.
This transformation enabled the encoding of semantic relationships in a way that machines could understand, such as the famous example:
vector("King") - vector("Man") + vector("Woman") ≈ vector("Queen")
This period also marked a shift towards distributed representations, a method where each word is represented by a set of values (or coordinates) across many dimensions, instead of being represented as a single point. By taking this approach, dimensionality of text data was significantly reduced (lowered the number of features needed to represent text), making the handling of large datasets much more effective. In simpler terms, instead of representing a word using a huge sparse matrix (where most values are zero), distributed representations allow us to represent words in a more compact and dense form, making computations less resource-intensive.
Word embeddings in turn alleviated some challenges associated with traditional text representation techniques like Bag-of-Words (BoW) - a representation technique that counts the occurrence of words within a document - or TF-IDF (Term Frequency-Inverse Document Frequency) - a technique that reflects how important a word is to a document in a collection or corpus - which often resulted in sparse (mostly zero values) and high-dimensional (many features) representations.
This transition helped lay a solid foundation for the development of more advanced NLP (Natural Language Processing) models, including Large Language Models (LLMs)
2014: Sequence-to-Sequence Model

The year 2014 witnessed the inception of sequence-to-sequence (Seq2Seq) models, pioneered by researchers Ilya Sutskever, Oriol Vinyals, and Quoc Le.
These models were meticulously engineered to handle sequences of data, both as input and output, marking a significant departure from previous models that were constrained by fixed-size input and output spaces.
A Sequence-to-Sequence model essentially consist of two recurrent neural network (RNN) architectures, comprising two primary components: an encoder and a decoder. The encoder processes the input sequence and compresses the information into a fixed-length context vector, which encapsulates the semantic essence of the input. The decoder, on the other hand, utilises this context vector to generate the output sequence. This bifurcation facilitates the model's ability to handle variable-length input and output sequences (sequences with different lengths), for example :
In translation, an input sequence of words in one language are encoded into a fixed-size vector representation, which is then decoded into an output sequence of words in another language.
By employing attention mechanisms (which allocate varying degrees of importance to different parts of the input sequence), these new models could focus on different parts of the input for different words in the output sequence, somewhat akin to how humans pay attention to different words when translating a sentence. This development not only showcased the potential in processing language data but also set the stage for future advancements, including the Transformer architecture.
2018: Attention is all you need
In 2018, the landscape of NLP witnessed a paradigm shift with the introduction of the Transformer architecture, encapsulated in the seminal paper, "Attention is All You Need" by Vaswani et al. This paper was both a revelation and a departure from conventional sequence processing models like RNNs and LSTMs.
At the heart of the Transformer architecture lies the Attention Mechanism, which challenged the sequential processing of data and offered a more parallel approach. Unlike its predecessors, the Transformer could process all words in a sentence in parallel, significantly reducing training times without sacrificing accuracy.
The Attention Mechanism empowers the model to focus on different parts of the input text when generating an output, similar to how humans pay attention to different words when comprehending a sentence. It weighs the importance of different parts of the input, allowing for a more nuanced understanding and handling of long-range dependencies in text.
For example, in the sentence "The cat sat on the mat", when translating this sentence, the attention mechanism helps in associating "cat" in English to its corresponding word in the target language, say, "gato" in Spanish.
.
UNDERSTANDING LLMs:

Architecture of LLMs
Large Language Models (LLMs) are primarily built on deep neural network architectures, consisting of multiple layers of interconnected nodes or neurons. These layers are stacked on top of each other, with each layer learning progressively more abstract representations of the input data.
Neural Networks: The foundational building blocks of LLMs, wherein a network of nodes mimics the way human brain processes information.
Layers: Neural networks in LLMs consist of multiple layers, including input, hidden, and output layers. Each layer transforms the data as it passes through, aiding in the extraction of features and relationships.
Nodes: The individual computational units in each layer that process the input data, applying mathematical transformations to extract information.
In the realm of Large Language Models, certain architectures have gained prominence due to their efficacy in handling language data:
1 - Transformer Architecture: The Transformer architecture, introduced in the seminal paper "Attention is All You Need" by Vaswani et al. in 2017, has become the backbone of most modern LLMs. Its self-attention mechanism allows it to process input sequences in parallel rather than sequentially.
2 - BERT (Bidirectional Encoder Representations from Transformers): BERT revolutionised NLP tasks by pre-training on a large corpus of text and fine-tuning on specific tasks. Its bidirectional context awareness (processing words in relation to all other words in a sentence, rather than in isolation) set new standards for a variety of NLP tasks.
3- GPT (Generative Pre-trained Transformer): GPT, and its subsequent versions like GPT-3, extend the Transformer architecture to generate coherent text over long passages - having been trained in an unsupervised manner on vast text corpora
Training LLMs
LLMs are trained in one of three ways:
.
Supervised Learning: In supervised learning, models are trained on labeled data, i.e., data paired with the correct output, facilitating the model in learning the mappings between inputs and outputs.
A prominent example of supervised learning in the context of LLMs is the fine-tuning of models like BERT for specific NLP tasks such as sentiment analysis, where the model is trained on a dataset of customer reviews labeled with positive or negative sentiments.
Supervised learning is widely used in many natural language processing applications like spam detection, where emails are classified into 'spam' or 'not spam' based on training on a labeled dataset.
.
Unsupervised Learning: Unsupervised learning involves training on unlabeled data, enabling the model to discover patterns and structures within the data on its own.
Word2Vec and GloVe are examples of unsupervised learning where models learn word embeddings by analyzing co-occurrences of words in large text corpora without any labels.
Unsupervised learning finds its application in topics discovery and document clustering where the model groups similar text documents together based on inherent patterns without prior labelling.
.
Semi-supervised Learning: A hybrid approach that utilizes a small amount of labeled data and a large amount of unlabeled data to train models, combining the benefits of both supervised and unsupervised learning.
The ULMFiT (Universal Language Model Fine-tuning) approach, where a language model is first pre-trained on a large corpus of unlabeled text data, then fine-tuned using a smaller dataset of labeled data for a specific task.
Semi-supervised learning is beneficial in scenarios where obtaining labeled data is expensive or time-consuming, but there is a plethora of unlabeled data available. It’s utilised in various NLP tasks including sentiment analysis, named entity recognition, and more.
PROCESS

Pre-training and Fine-tuning:
Before being deployed for specific tasks, LLMs undergo a two-step training process: pre-training and fine-tuning. Pre-training involves training the model on a large corpus of text data to learn general language representations. This process might come before the steps you outlined, setting the stage for the rest of the journey.
Parameter Updating (Training):
The process of adjusting the model's parameters (weights and biases) based on the error or loss during training is critical. This fine-tuning of parameters occurs during the backpropagation step, ensuring the model learns and improves its performance over time.
Evaluation and Testing:
After the model is trained and fine-tuned, it's crucial to evaluate its performance on unseen data. This evaluation helps to gauge the model's ability to generalize and perform well on the task at hand.
Loss Computation:
Calculating the loss, the discrepancy between the model's predictions and the actual data, is a pivotal step. It guides the updating of the model’s parameters.
Optimization Algorithms:
Optimization algorithms like Adam or Stochastic Gradient Descent (SGD) play a crucial role in adjusting the model's parameters during the training phase, steering the model towards better performance.
Hyperparameter Tuning:
Selecting the right set of hyperparameters (like learning rate, batch size, etc.) is vital as it significantly impacts the model's learning process and performance.
Regularization:
Techniques like dropout or L2 regularisation are employed to prevent overfitting, ensuring the model generalises well to unseen data.