
Philosophy of Science
A Journey from Foundational Truths to Practical Insights.


I was once asked, what is the science in data science. I didn’t know how to answer it … and the only thing that came to my mind was hypothesis testing.As data scientists, we form hypotheses and test them, either proving or failing to prove the null hypothesis, thereby adhering to the scientific method. I knew this answer was lacking depth and even the answer I had given, I’m not sure I really understood. So I decided to study a course on the ‘Philosophy of Science’ at the University of Oxford to really understand the parallels of science, philosophy and data science!
In this post, we'll explore the connection between the Philosophy of Science and Data Science - starting by understanding key philosophical ideas from thinkers like Karl Popper and Thomas Kuhn, and see how these ideas have shaped scientific inquiry over centuries. We'll delve into the world of Data Science, looking at how these philosophical principles find application in modern data analysis and decision-making and touch on some challenges like bias and ethical considerations that come with big data, and see how a philosophical grounding can help address them.
If you haven’t read the earlier post, 1st Rule of Machine Learning, See Below
1st Rule of Machine Learning

Machine learning (ML) is a powerful tool, but it's not always the first solution we should turn to… Rule 1 of Machine Learning: “Don’t use Machine Learning” . No Machine Learning you say? Diving straight into ML can be tempting, especially with the buzz it has generated. However, ML requires a robust data pipeline, high-quality…
Let’s delve into the Philosophy of Science and its shaping of scientific inquiry.
Introduction to philosophy of science:
The realm of data science is deeply entrenched in scientific principles, yet the 'science' in data science often sparks curiosity and necessitates a deeper dive. This is where a foundation in the philosophy of science can be hugely beneficial.
At its core, the Philosophy of Science examines the very nature of scientific inquiry. It delves into how we acquire knowledge, how we prove theories, and how we discern verifiable facts from mere assumptions. Over centuries, this field of philosophy has evolved, introducing frameworks that guide how we approach scientific problems, test hypotheses, and validate findings.

.
In today's world, data is a big deal—it guides decisions in almost every sector - and Data Scientists are key to extracting value from it. That 'science' in Data Science, the scientist in Data Scientist is rooted in philosophical principles that have evolved over centuries. The idea of testability from Karl Popper teaches us that our data models should be able to be tested and proven wrong. This keeps our analyses accurate and reliable.
Thomas Kuhn’s concept of paradigm shifts encourages us to stay open to new ways of interpreting data, which can lead to innovative solutions. As we dig through data, the skepticism introduced by René Descartes helps us question and validate our findings, making our conclusions stronger.
The insights from Ludwig Wittgenstein and Willard Van Orman Quine about language help us understand the complex narratives within data. These philosophical ideas help address modern challenges in Data Science like dealing with bias, making ethical algorithmic decisions, and handling privacy concerns. So, when we talk about Data Science, we're also talking about a rich philosophical legacy that helps us navigate the complex data landscape responsibly and effectively.
.

.
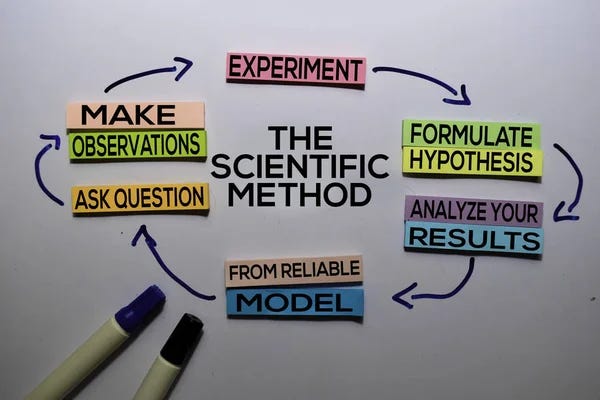
The Scientific Method
.
The Scientific Method is deeply rooted in the philosophy of science, with contributions from notable philosophers such as Aristotle, Karl Popper, and Thomas Kuhn. It is a systematic and iterative process that involves several core principles:
.
Observation:
Observation is often always the first step and holds a paramount position in the discourse of scientific methodology.
Aristotle, a proponent of empiricism, posited that all knowledge originates from sensory experiences, emphasising empirical observation as the foundational step for scientific inquiry.
This Aristotelian perspective laid the groundwork for empiricism, a philosophical position asserting that knowledge is primarily derived from sensory experience.
Beyond Aristotle, empiricists like John Locke and David Hume further expounded on the role of sensory experience in the acquisition of knowledge. Locke posited that the mind at birth is a tabula rasa, a blank slate, and it is through sensory experiences and reflections that we acquire knowledge. Hume, extending this empiricist tradition, argued that our beliefs and understandings are the products of our sensory impressions and the associations we form between them.
.
.
Observation is the process of recording and analysing data to discern patterns, anomalies, or phenomena, often necessitating some form of explanation. It is the first step in the scientific method, serving as the basis for hypothesis formation and experimentation.
.
.
Understanding the Scientific Method leads us to the pivotal issue of demarcation—differentiating authentic science from pseudoscience. Let's delve into how philosophers like Karl Popper have navigated this dilemma.
Demarcation Between Science and Pseudoscience
.
The path of distinguishing science from its ‘imitators’, often termed pseudoscience, has been a long-standing challenge in the philosophy of science. This distinction, known as the demarcation problem, seeks to establish clear criteria that differentiate authentic scientific inquiry from pseudoscience - claims, beliefs, or practices that guise as science.
.
Karl Popper and Falsifiability:
Central to this discourse is the philosopher Karl Popper, who introduced a criterion to differentiate between science and pseudoscience called falsifiability.
.
.
Popper posited that for a statement or theory to be considered scientific, it must be susceptible to being proven false. Put simply, a genuine scientific hypothesis or theory is one that, in principle, can be refuted by empirical evidence. This emphasis on falsifiability challenges the notion that science progresses solely through verification, underscoring the importance of refutability as a definition of scientific rigour.
.
.
Pseudoscientific claims either lack empirical support or are inherently unfalsifiable. Take for example, horoscopes - they offer vague and general predictions that can never be refuted with specificity, rendering them pseudoscientific.
Such claims, while often presented with the trappings of science, fail to meet the rigorous criteria of testability and falsifiability that define genuine scientific inquiry.
.
Demarcation in Data Science:
.
The demarcation problem finds relevance in the realm of Data Science as well. As data-driven models and algorithms become increasingly integral to decision-making, it's crucial to discern between models grounded in sound scientific principles and those based on spurious correlations or unfounded assumptions.
.
.
Just as Popper's falsifiability criterion distinguishes science from pseudoscience, in Data Science, the validity of models must be assessed based on their predictive accuracy, transparency, and susceptibility to empirical validation. Models that cannot be tested, validated, or refuted based on real-world data tread dangerously close to the realm of pseudoscience.
.
.

.
Let’s now bridge these age-old philosophical ideas with modern Data Science practices, where empirical evidence serves as the cornerstone for deriving insights and making informed decisions
Empiricism
Empiricism is a philosophical approach that emphasises the role of experience, especially sensory perception, in the formation of knowledge - i.e. knowledge is rooted in our experiences and observations. It is in stark opposition to the notion that knowledge can be derived solely from reason or innately. Empiricism gained significant traction during the Early Modern period with key figures like John Locke, George Berkeley, and David Hume being instrumental in its development. They challenged the dominant rationalist views of their time, emphasising the importance of empirical evidence.
.
Key Principles
Sensory Experience: Empiricists believe that all knowledge originates from sensory experience. Our senses are the primary source of information about the world.
Inductive Reasoning: Empiricism often relies on inductive reasoning, where general conclusions are drawn from specific observations.
Rejecting Innate Ideas: Empiricists challenge the notion that we are born with certain ideas or knowledge. Instead, the mind is seen as a tabula rasa - a blank slate, shaped by experience.
.
Criticisms : While empiricism has been influential, it's not without its critics. Some argue that relying solely on sensory experience can be limiting. Others point out that our senses can sometimes deceive us, leading to incorrect conclusions. Additionally, there are debates about the nature of concepts and whether they can be entirely derived from experience.
.
.
Data Science and Empiricism
In the field of Data Science, data scientists gather vast amounts of data from various sources, which in essence serves as empirical evidence. This data is processed, analysed, and interpreted (what is otherwise called EDA) to derive meaningful insights and make informed decisions.
.
Just as empiricists believe that knowledge comes primarily from sensory experience, data scientists believe that actionable insights come from rigorous data analysis. The methodologies used in Data Science, such as statistical analysis, machine learning, and predictive modelling, are all grounded in the empiricist tradition, emphasising observation, experimentation, and most importantly evidence-based conclusions.
.
Empiricism in Data Science, is not without its challenges. One of the primary concerns is data quality. The integrity of the conclusions drawn from empirical research depends very much on the quality of the data collected. Poor data quality can lead to misleading or incorrect insights.
.
Another significant challenge is bias. Bias can creep into empirical research in various ways, from the design of the experiment or survey to the interpretation of the results. For instance, if a data set is not representative of the population it's meant to represent, the conclusions drawn from it may be skewed. Here are some further examples of bias:
.
Selection Bias: This occurs when the data used for analysis is not representative of the larger population.
Confirmation Bias: Researchers, consciously or unconsciously, might seek out data or interpret results in ways that confirm their pre-existing beliefs or hypotheses.
Measurement Bias: This arises when data is collected using flawed measurement tools or methods.
.
Lastly, interpretation is a critical challenge. Even with high-quality, unbiased data, the interpretation of the results requires careful consideration. Misinterpretation can lead to incorrect conclusions, which can have significant implications, especially in fields like Data Science where decisions based on data can impact businesses, economies, and societies.
.
Model Interpretation: LIME and SHAP: Model interpretation in Data Science is crucial for ensuring fairness, accountability, and transparency of predictive models. Two prominent methods in this domain are LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations).
.
LIME focuses on explaining individual predictions by approximating complex models with simpler, interpretable models for individual predictions. On the other hand, SHAP values, inspired by the Nobel prize-winning Shapley values from cooperative game theory, allocate the contribution of each feature to every prediction made by the model.
.
.

.
Epistemology
Epistemology, at its core, is the study of knowledge. It delves into the nature, origin, and limits of human understanding. It views knowledge as static and absolute, grounded in objective truths and verifiable facts - seeking to answer questions like: "What is knowledge?", "How is knowledge acquired?", and "To what extent can something be known?"
Data Science is an interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It challenges traditional epistemological notions in several ways:
Traditional epistemology often views knowledge as static and absolute. In contrast, data science sees knowledge as dynamic, evolving with new data and insights.
Data science emphasises empirical evidence derived from data. This contrasts with knowledge based on intuition, authority, or philosophical reasoning alone.
Again, traditional views consider truth as binary (true or false), whilst data science works in probabilities and uncertainties.
.
Bayesian reasoning and probabilistic modeling :
Bayesian Reasoning is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available.It incorporates prior knowledge or beliefs, which are then updated with new data. This is especially useful in situations with limited data as it allows data scientists to build models that capture the inherent uncertainties in real-world phenomena, leading to more robust and adaptable conclusions.
Bayesian reasoning is a way of calculating the likelihood of something happening based on the information we have. It's like adjusting your estimate of how likely it is to rain today based on whether you see dark clouds in the sky."
.
The need for critical thinking:
While data science offers powerful tools for extracting knowledge, it's not without limitations:
Bias and Fairness:
.
Data-driven models are only as good as the data they are trained on. If the data reflects societal biases, the model will too. For instance:
Historical Bias: Data often captures historical prejudices. For example, if a hiring algorithm is trained on past hiring decisions that favoured a particular gender or ethnicity, it might perpetuate that bias in its future recommendations.
Sampling Bias: If the data doesn't representatively sample from all sections of the population, the model's predictions can be skewed. For instance, a health app primarily used by younger individuals might not be as effective for elderly users.
Addressing Bias: It's vital for data scientists to be aware of potential biases in their data and to take steps to mitigate them. Techniques like re-sampling, using fairness-enhancing interventions, and employing adversarial training can help in reducing model bias.

.

Over-reliance on Data:
.
Overfitting: This occurs when a model learns the training data too closely, including its noise and outliers, making it perform poorly on new, unseen data. It's like memorising answers for an exam without understanding the concepts.
Spurious Correlations: Just because two variables correlate doesn't mean one causes the other. For instance, a correlation between ice cream sales and drowning incidents doesn't mean one causes the other; both are influenced by the summer season.
Contextual Interpretation: Data scientists must always interpret their findings in the context of the broader domain. External factors, not present in the data, can often influence outcomes.
.
Ethical Considerations:
.
The rise of big data and advanced analytics has brought several ethical challenges to the forefront:
Privacy Concerns: With the ability to collect and analyse vast amounts of data, there's a risk of infringing on individuals' privacy. Even "anonymised" data can sometimes be de-anonymised using advanced techniques.
Informed Consent: Just because data about individuals is available doesn't mean it's ethical to use it. Users should be informed about how their data will be used and given a choice to opt out.
Transparency and Accountability: As algorithms play an increasingly significant role in decision-making, it's crucial for them to be transparent. If a model denies someone a loan or a job opportunity, they have a right to know why.
.
3 Takeaways
Here are the top 3 personal takeaways from my study:
.
Testability and Falsifiability: Drawing from Karl Popper's philosophy, the essence of scientific inquiry lies in its ability to be tested and potentially refuted. This principle is paramount in data science, ensuring models and theories are grounded in evidence and open to scrutiny.
Standardisation and Documentation: As the adage goes, "If you solve a problem, standardise it." Consistency and thorough documentation are vital for repeatability, allowing others to build upon or challenge established work.
Ethical and Epistemological Considerations: Contemporary thinkers like Judea Pearl and Cathy O'Neil emphasise the importance of transparent and accountable models in data science. Beyond mere prediction, there's a pressing need for models that can explain their reasoning, ensuring ethical and informed decision-making.
.